이 글은 보안 분석가, 리버스 엔지니어, 안드로이드 앱의 내부 동작 원리에 깊은 관심이 있는 개발자를 대상으로 합니다.
로그에서 코드로: 실행 흐름을 되살리다
지난 PART 1에서 우리는 NMMP가 자바 바이트코드를 가상머신 뒤로 감추는 방식을 살펴봤습니다. 또한 앱 실행 중 남는 단서들(ART Resolve 호출, JNI 룩업, 문자열 라벨)이 분석의 결정적인 실마리가 됨을 확인했습니다.
이번 PART 2에서는 앞서 확인한 내용을 바탕으로 실제 검증 과정을 공유하고자 합니다. 샘플 앱을 실행 시 발생하는 단서들을 시간순으로 배열하고 그 흐름을 사람이 읽을 수 있는 최소한의 자바 코드로 복원해 보겠습니다. 퍼즐 조각을 맞추듯 로그 한 줄 한 줄이 어떻게 실행 가능한 코드의 형태로 되살아나는지 확인해 보시기 바랍니다.
Opcode 분석은 왜 어려운가?
가상화 기반 난독화를 수행하는 NMMP는 자바 바이트코드를 커스텀 바이트코드로 변환하고 자체 가상머신 위에서 실행합니다. JADX 디컴파일러로 NMMP 난독화가 적용된 앱을 열어보면 아래 그림처럼 빈 네이티브 메서드 선언만 보일 뿐입니다.

[그림 1] 네이티브 메서드 선언 (실제 로직은 NMMP 내부에 숨겨짐)
핵심이 되는 구현부는 가상머신 내부에 숨겨져 있어 정적 분석만으로는 접근이 어렵습니다. 이때 “opcode를 직접 해석하면 되지 않을까?“라고 생각할 수 있습니다. 하지만 이 방법은 현실적으로 쉽지 않습니다. 빌드 때마다 opcode 매핑이나 디스패처 구성이 달라지고 때로는 핸들러가 인라인 처리되거나 병합되기도 합니다. 게다가 불필요한 분기나 조건을 삽입해 실행흐름을 의도적으로 복잡하게 만들기도 합니다.
관점의 전환: opcode가 아닌 의미를 복원한다
따라서 관점의 전환이 필요합니다. 명령어 목록(opcode list)을 나열하는 대신 의미 지도(semantic map)를 그리는 접근법이 훨씬 효율적입니다.
즉, “무슨 명령이 실행됐나?” 보다는 “무엇을 읽고, 어떤 조건을 거쳐, 어디로 보냈는가?"라는 질문에 답하는 실행형 로드맵을 만드는 것이죠. 이렇게 하면 난독화된 코드 뒤에 숨은 본래의 로직을 훨씬 명확하게 파악할 수 있습니다.
opcode 구조를 완전히 파악하지 않고도 로직을 복원하는 열쇠는 ‘런타임 실행 흔적’에 있습니다. 앱이 실행될 때 보호 레이어가 남기는 단서들을 시간 순서대로 연결하면 원래 코드의 실행 흐름이 서서히 드러납니다.
코드 복원을 위한 세 가지 관찰 포인트
실제 실행 경로를 파악하려면 런타임 추적이 필수적입니다. 메서드 이름이나 객체 정보는 런타임(JNI나 ART resolve가 동작하는 순간)에 비로소 확정되기 때문입니다.
런타임 추적 시에는 ‘이름(Name), 맥락(Context), 바인딩(Binding)’의 세 가지 단서에 집중해야합니다. 각 단서는 우리가 수집하는 게이트와 1:1 대응이 이루어집니다.
첫 번째 단서: 이름(Name) 찾기 - JNI Lookup
아래와 같이 Frida 스크립트를 작성하여 실행하면 앱이 사용하는 이름 중 SMSUtils→getSmsInphone이라는 메서드를 확인할 수 있습니다. 이는 앱이 SMS 데이터 수집을 수행하고 있음을 보여줍니다.
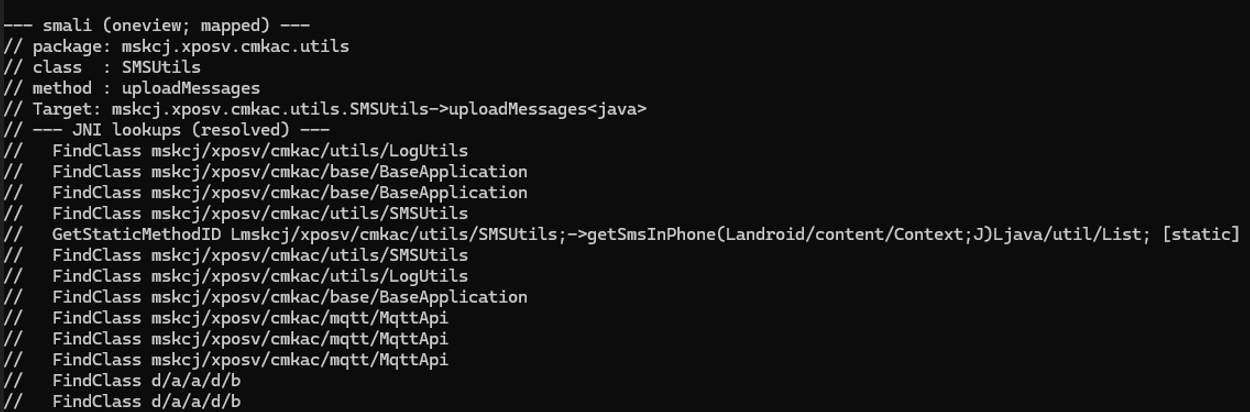
[그림 2] JNI Lookup 확인
이러한 이름을 확인하기 위해 Frida 스크립트를 아래와 같이 작성 합니다.
// JNI 클래스/ID 추적*
attachSymbols('libart.so', pred(['JNI','FindClass']), {
onEnter(args){ this._name = args[1]? args[1].readCString():null; },
onLeave(ret){
if (ret && !ret.isNull() && this._name){
classNameByJClass.set(ret.toString(), this._name);
const a=activeAgg();
if (a) a.jniResolved.push({kind:'FindClass', text:this._name});
}
}
});
*// GetMethodID, GetStaticMethodID도 동일하게 훅*
function hookGetID(tag){
attachSymbols('libart.so', pred(['JNI',tag]), {
onEnter(args){
const owner = classNameByJClass.get(args[1].toString());
const name = args[2].readCString();
const sig = args[3].readCString();
const line = owner? ('L'+owner+';->'+name+sig) : null;
if (line) pushEvt('jni:'+tag, line);
}
});
}
두 번째 단서: 맥락(Context) 붙이기 - Reference Map
실행 중 남는 문자열, 스레드명, 타입명 등은 흐름을 파악하는 라벨 역할을 합니다. 예를 들어 “smsList is null or empty"와 같은 문자열이 발견된다면 현재 단계가 데이터 수집, 필터링, 혹은 전송 준비 중 어디에 해당하는지 유추할 수 있습니다. 이러한 라벨을 태그처럼 모아두면 재분석 속도를 높일 수 있을 뿐 아니라 다른 샘플과의 패턴 비교도 용이해집니다.
Reference Map(Ref Map) 구축하기
Reference Map(이하 Ref Map)은 VM 실행 중에 참조되는 모든 심볼 정보를 수집한 맵입니다. 여기서 말하는 ‘Reference’는 VM이 ART 환경에서 동적으로 찾아오는 클래스, 메서드, 필드, 문자열 등의 참조를 의미합니다.
이 개념은 JVM이나 GC 내부에서 객체 참조를 추적할 때 사용하는 reference map과 유사한 맥락으로 실행 시점의 모든 참조 관계를 기록한다는 점에서 같은 이름을 사용합니다.

[그림 3] Ref Map 확인
위 그림은 Frida로 수집한 Ref Map 출력 결과입니다. "pool-2-thread-2"와 같은 문자열 참조가 시간순으로 기록되어 있습니다.
이러한 문자열 풀과 리플렉션 정보를 수집하는 Frida 스크립트는 다음과 같이 구현할 수 있습니다.
// Dex 문자열 수집*
attachSymbols(so, s=>/DexFile/.test(s.name)&&/(StringData|GetString)/.test(s.name), {
onEnter(args){
this._idx = asU32(args[1]);
},
onLeave(ret){
const txt = ret.readCString();
if (txt && !looksLikeRes(txt)) {
strPool.set(this._idx, txt);
addIdx('s', this._idx);
}
}
});
이렇게 구축한 Ref Map은 랜덤화된 Opcode를 해독하지 않고도 실제 실행 흐름을 파악할 수 있는 강력한 도구가 됩니다.
세 번째 단서: 바인딩(Binding) 확정하기 - Event Trace
ART의 ClassLinker::ResolveMethod나 ResolveField 함수에서 method@#### 형태의 인덱스가 실제 호출 대상으로 변환되는 순간을 포착해야 합니다. 바로 이 시점에 분기의 목적지가 확정되는거죠. 예를 들어, 이 지점 직후의 호출이 MQTT 전송으로 이어진다면 이를 앵커(Anchor)로 삼아 실제 실행 순서를 명확하게 복원할 수 있습니다.
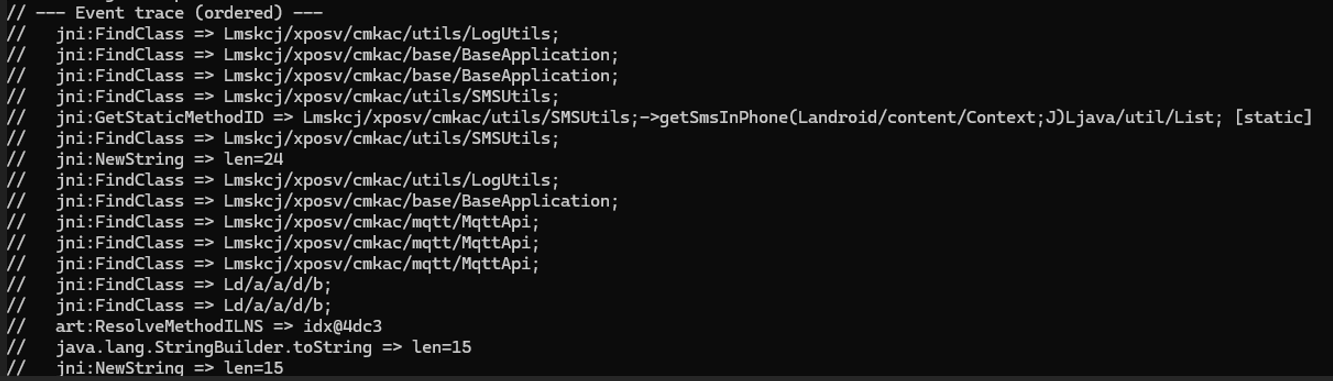
[그림 4] Event Trace 확인
Event Trace 정보는 아래 스크립트로 수집할 수 있습니다.
// ClassLinker resolve로 idx 수집*
function hookClassLinker(){
Module.enumerateSymbolsSync('libart.so').forEach(s=>{
if (s.name.indexOf('ClassLinker')>=0 && names.some(n=>s.name.indexOf(n)>=0)){
Interceptor.attach(s.address,{
onEnter(args){
let idx = asU32(args[1]);
if (idx != null){
const tag = s.name.match(/Resolve[A-Za-z]+/)[0];
pushEvt('art:'+tag, 'idx@'+hx(idx,4));
if (tag.indexOf('Method')>=0) addIdx('m', idx);
}
}
});
}
});
}
이제 idx@4dc3이 getSmsInPhone으로 해석된다는 사실을 알아냈습니다. 남은 작업은 이 지점 직후에 어떤 호출이 이어지는지 추적하는 것뿐입니다.
세 단서를 연결하면 흐름이 보인다
이름으로 ‘무엇을’, 맥락으로 ‘언제/왜’, Event Trace로 ‘어디로’ 갔는지 확정하면 opcode를 완벽히 이해하지 못해도 코드의 실행 의미가 자연스럽게 드러납니다. 이 세 가지 단서만 유기적으로 연결된다면 가상머신 내부의 복잡한 디스패처 구조를 일일히 분석하지 않고도 사람이 읽을 수 있는 형태로 로직을 복원할 수 있습니다.
단서에서 코드로: 복원 과정
앞서 수집한 세 가지 단서를 어떻게 코드로 변환하는지 살펴보겠습니다. 먼저 런타임 로그에 남은 이름(JNI Lookup)으로 실제 호출 대상을 고정합니다. 다음으로 맥락(Ref Map)으로 분기 의도와 실행 환경을 덧붙입니다. 마지막으로 Event Trace를 통해 메서드 인덱스와 실제 호출 대상의 연결 시점을 확인하여 전체 흐름을 시간순으로 매핑합니다.
이렇게 시간순으로 정렬된 의미 조각들을 AI에게 입력하면 최소한의 자바 골격으로 펼쳐진 코드가 완성됩니다. 흐름을 요약하면 [컨텍스트 확보 → 단말에서 데이터 수집 → 빈 목록 확인 → 전송 단계]로 이어지며, 단서들이 연결되어 실행 가능한 코드 형태를 갖추게 됩니다.
그렇다면 복원된 코드는 제대로 복원된 걸까요? 복원본을 원본 코드와 비교하면서 검증해 보겠습니다.
원본 VS 복원: 흐름이 유사한가?
복원된 코드를 원본과 비교해 보았습니다. 위쪽이 원본 자바 코드, 아래쪽이 AI로 복원한 코드입니다. 두 코드를 대조해보면 의도와 실행 순서가 사실상 동일함을 알 수 있습니다.
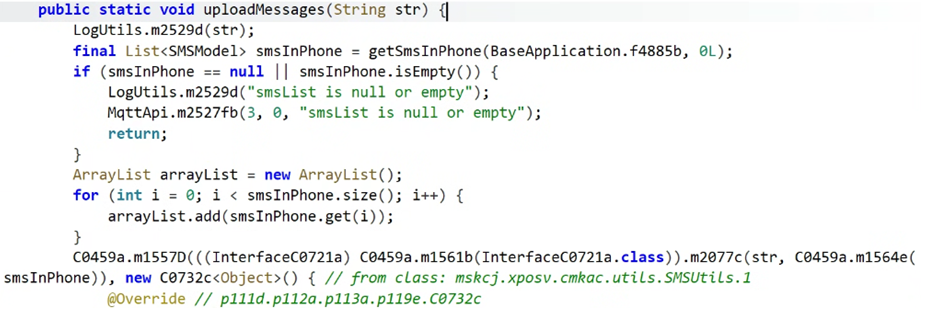

[그림 5] (상) 원본 자바 코드 / (하) AI로 복원된 자바 코드
실제 흐름을 살펴보면 가장 먼저 애플리케이션 컨텍스트를 확보한 뒤 단말에서 SMS 목록을 수집합니다. 만약 수집된 목록이 비어 있다면 로그를 남기고 즉시 종료하지만 데이터가 존재한다면 MQTT 전송 계층을 준비해 메시지를 순차적으로 전송하는 구조를 따릅니다. 즉, 컨텍스트 확보 → SMS 수집 → 빈 목록 확인 → MQTT 전송이라는 전체 흐름이 처음부터 끝까지 원본과 유사하게 진행됩니다.
복원이 정확한 이유
런타임 추적 결과는 확정적인 증거를 제시합니다. JNI Lookup으로 SMSUtils.getSmsInPhone(...)과 mqtt.MqttApi를 식별해 “무엇을 쓸지” 정했고, Ref Map의 "smsList is null or empty" 문자열을 통해 빈 목록을 처리하려는 분기 의도를 파악했습니다. 이어지는 Resolve 이벤트는 분기 직후 호출 대상을 MQTT 전송 경로로 고정하며 목적지를 확정 지었습니다. 결국 세 가지 단서가 모두 같은 방향을 가리키고 있었던거죠.
복원의 타당성을 체계적으로 검증하기 위해 네 가지 핵심 항목을 체크했습니다.
- ① 데이터 진입점: 어디서 실행이 시작됐나? →
getSmsInPhone
- ② 분기: 중간에 어떤 조건을 검사했나? →
"smsList is null or empty"
- ③ 데이터 종착지: 최종적으로 어디로 데이터가 전달됐나? → MQTT 전송
- ④ 호출 흐름: 어떤 순서로 메서드가 호출됐나? → 컨텍스트 → 수집 → 확인 → 전송
네 가지 항목 모두 원본과 유사합니다.
유사도는 얼마나 될까?
복원된 코드는 얼마나 비슷할까요? 주관적인 해석을 배제하고 객관적인 수치를 확인해보고 싶었습니다. 그래서 두 코드를 ChatGPT에게 입력하여 구조적 유사성을 물어봤습니다.
ChatGPT가 잠시 생각하고는 답변을 돌려줬습니다. “유사도 85%"
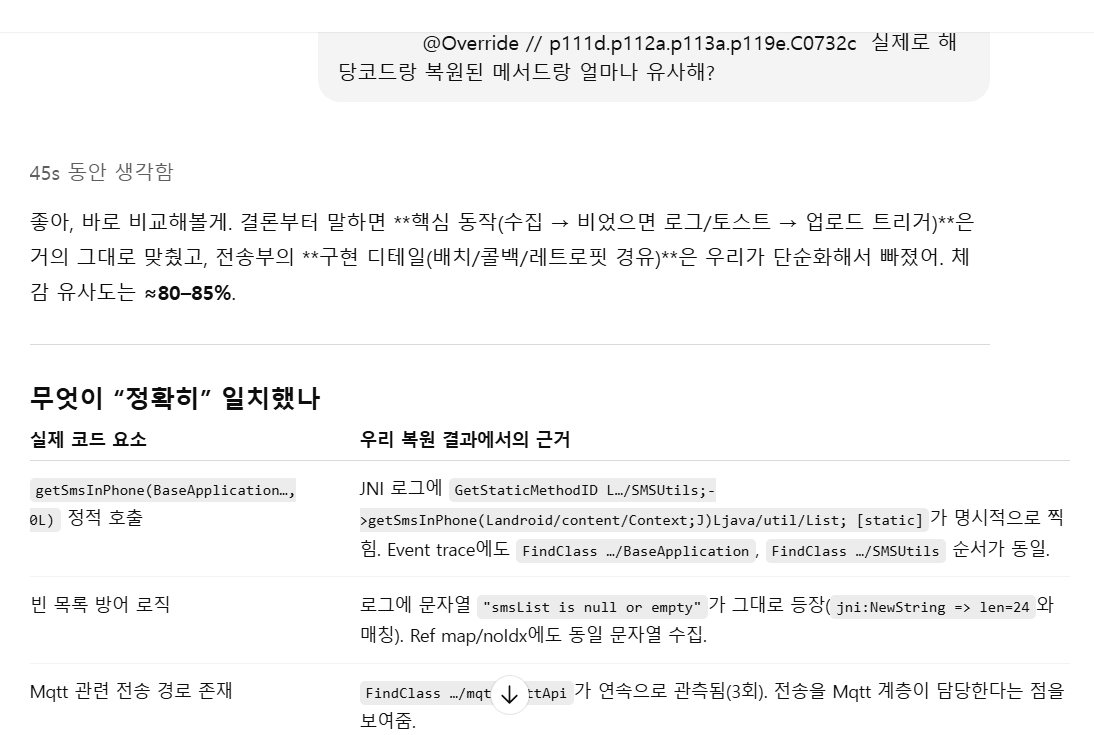
[그림 5] 자바 코드 유사도 (ChatGPT)
이 85%라는 수치는 시사하는 바가 큽니다. 데이터 수집 진입점(getSmsInPhone), 분기 조건(smsList is null or empty), 도착지인 MQTT 전송, 그리고 호출 순서까지 핵심 실행 흐름이 원본과 유사하다는 뜻입니다. 남은 15%는 로그만으로는 확정하기 어려운 배치 처리, 재시도 로직, 콜백 타이밍 등의 세부 구현 사항이지만 이는 전체 기능의 목표나 흐름을 바꾸지는 않습니다.
결론: OP를 몰라도 복원은 가능하다
정리하면 이렇습니다. NMMP처럼 opcode 매핑이 빌드마다 바뀌는 환경이라도 이름·맥락·바인딩 세 가지 단서만 확보하면 OP 구조를 완전히 이해하지 못해도 원본과 거의 동일한 실행 서사를 재구성할 수 있습니다. 이번 사례에서 확인한 85%의 유사도가 이를 증명합니다.
빈 네이티브 메서드들 내부에서 실제로 무슨 일이 일어나는지 opcode를 하나하나 해석하며 추적하려면 엄청난 시간이 필요합니다. 가상머신 내부의 디스패처 구조를 분석하고, 빌드마다 바뀌는 opcode 매핑 테이블을 복구하고, 인라인된 핸들러 로직을 재조립해야 하니까요.
하지만 우리가 진짜 알고 싶은 건 ‘opcode의 기계적 의미’가 아니라 ‘코드가 수행하는 실질적 행위’입니다. 그리고 그 질문에 대한 답은 세 가지 단서만으로도 충분히 얻을 수 있었습니다.
이번 PART 2를 통해 NMMP 분석의 실전 검증까지 모두 마쳤습니다. 앞으로도 계속해서 진화하는 모바일 위협과 그에 맞서는 분석 기법들을 깊이 있게 다뤄보겠습니다.
긴 글 읽어주셔서 감사합니다.
기술 용어 정리
- Opcode: 바이트코드 명령을 식별하는 번호입니다. 빌드마다 매핑이 변경될 수 있습니다.
- 핸들러(Handler): 특정 옵코드를 실제 동작으로 처리하는 함수 또는 루틴입니다.
- 디스패처(Dispatcher): 읽은 옵코드를 해당 핸들러로 분기시키는 루틴입니다.
- JNI Lookup: FindClass, GetMethodID, NewString 등으로 실제 클래스·메서드·문자열 이름을 확인하는 단계입니다.
- ClassLinker::Resolve / Resolve 이벤트: ART가
method@####, type@#### 같은 DEX 인덱스를 실제 심볼(호출 대상 등)로 바인딩하는 순간입니다.
- Event Trace: Resolve 등 런타임 이벤트를 시간순으로 나열한 실행 기록입니다.
- Ref Map: 실행 중 남는 문자열·스레드명·타입명 등을 묶어 흐름을 식별하는 라벨 집합입니다.
- 컨텍스트(Context): 실행에 필요한 환경이나 상태를 말합니다. 예를 들어 애플리케이션 컨텍스트 같은 것이죠.
- MQTT: 전송 채널로 사용된 경량 메시지 전송 프로토콜입니다.



 Jiwon
Jiwon
